Emilio Carrión
El ADN del software no era un concepto. Era 24 archivos.
Hace tres semanas defendí que el código se iba a volver desechable y lo importante sería el ADN del software. Me encerré a comprobar si esa idea era escribible de verdad. Lo que sale: 24 archivos, dos regeneraciones por menos de un euro cada una, un repo público, y bastante claridad sobre lo que el harness engineering aún no resuelve.
- 1Cuando los LLMs generen miles de tokens por segundo, lo que importa no será el código
- 2El ADN del software no era un concepto. Era 24 archivos.
Hace tres semanas saqué la bola de cristal e intenté adivinar el futuro 🔮: cuando los LLMs generen miles de tokens por segundo, regenerar código será más barato que mantenerlo (y más rápido incluso que leerlo!). Y entonces la pregunta deja de ser "¿cómo escribo bien código?" y pasa a ser "¿qué información permite regenerar este sistema sin perder su identidad?". A esa información la llamé ADN.
Esa tesis tenía un problema. Era abstracta. Y como reconocí al final del post, las tesis abstractas envejecen mal cuando no se aterrizan. Así que me he sentado tres semanas a comprobar si el ADN era escribible de verdad o solo sonaba bien.
Lo es. Son 24 archivos.
Por qué un producto y no un microservicio
En los equipos con los que trabajo, la conversación que más se repite estos meses no va de cuánto código genera el agente. Va de cuánto tenemos que rehacer cuando lo que produce no encaja con lo que el sistema necesita. Y eso no se arregla revisando con más cuidado. Se arregla en lo que le damos al agente antes de que empiece.
El experimento del post anterior fue con un microservicio. Backend. Y un microservicio es generoso con quien lo regenera: tests, contratos, schemas. Si el agente cumple los tests, ha hecho el trabajo.
Un producto completo es otro tema. La verificación debe incluir cosas como "el menú comunica el tipo de cocina en menos de diez segundos" o "el botón de reserva sigue funcionando si el iframe del proveedor está caído". Eso no se expresa en OpenAPI. Y esto es lo que cambia las cuentas: la mayoría del software que nos pagan por construir vive en este grupo. Landings, microsites, dashboards internos, herramientas. Si el modelo del ADN solo funciona para microservicios, es una parte pequeña del negocio. Si funciona para producto, toca a la mayor parte de lo que construimos.
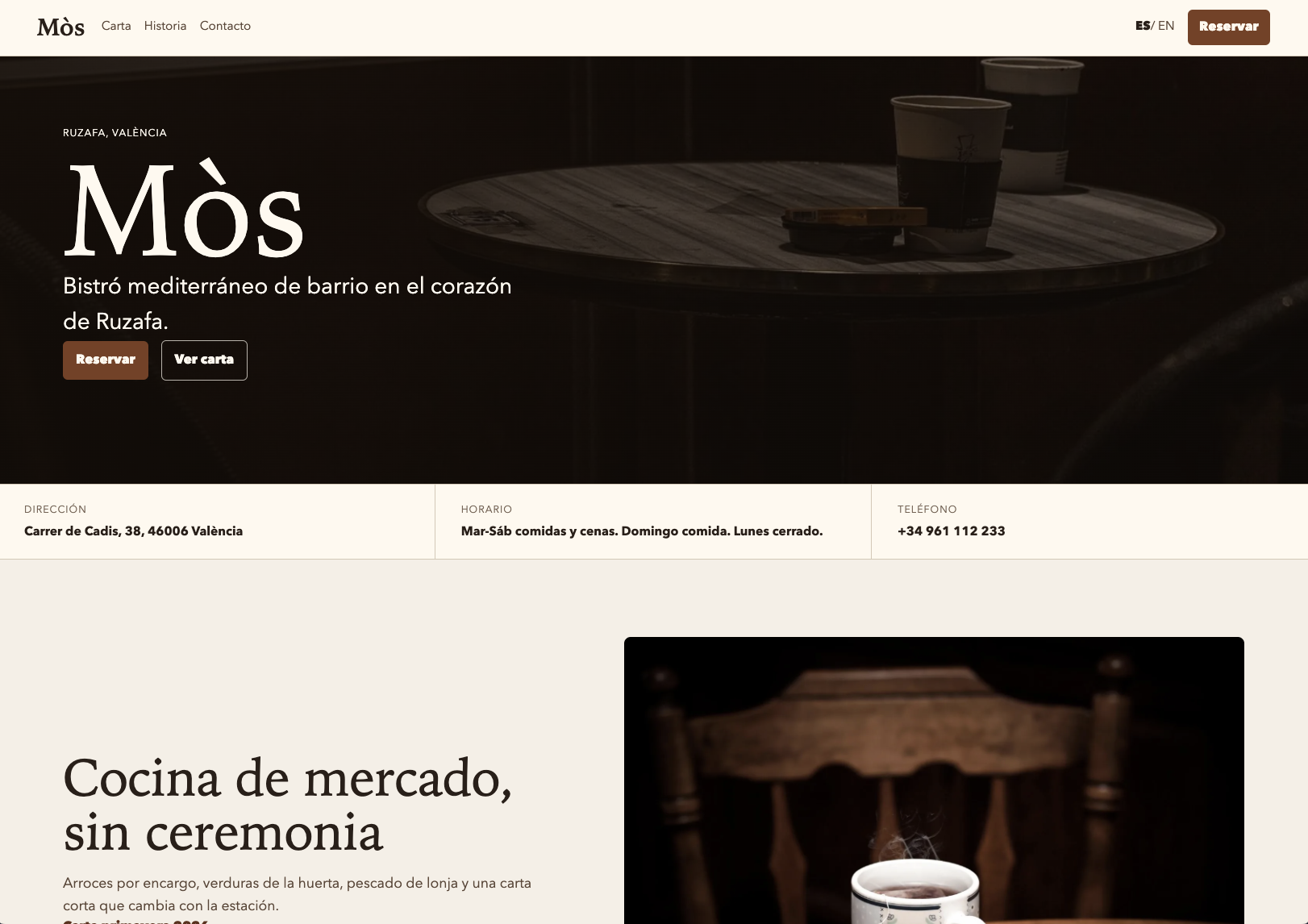
Por eso fui al caso difícil. Cogí Astro, Tailwind, TypeScript estricto, Codex CLI con GPT-5 e inventé un restaurante mediterráneo en Ruzafa que se llama Mòs. Empecé a escribir el ADN con la mejor estructura que se me ocurrió y le di al botón. Dos regeneraciones. La primera fue un poco desastre, pero falló en sitios que me enseñaron qué le faltaba al ADN. La segunda salió razonable.
Lo que va a cambiar la dinámica de la economía del software: cada regeneración entera de Mòs cuesta menos de un euro en tokens. No es una hipótesis sobre 2028, es lo que costó la semana pasada con un modelo de hoy. Y eso cambia las cuentas: si regenerar un producto entero cuesta menos que un café, lo caro deja de ser el código. Lo caro es no haber escrito bien lo que se regenera.
Esto es lo que salió del run #2. Nada del color, la tipografía o las fotos estaba especificado en el ADN: el agente derivó toda la estética desde prosa.
Los 24 archivos
Si no quieres mirar el árbol entero, la idea en una línea: tres carpetas, una para qué hace el producto, una para con qué se construye, una para los datos concretos. Más dos archivos de cabecera (uno para el humano que forkea, otro para el agente que regenera). Para el resto, esto es lo que aparece cuando abres el blueprint:
restaurant-website/
README.md ← para el humano que forkea: qué produce el blueprint
AGENTS.md ← para el agente: qué hacer, en qué orden, qué entregar
species/ ← lo que define el género, invariante
capabilities.md ← qué debe poder hacer (criterios verificables)
quality.md ← cómo lo hace bien (performance, a11y, UX)
rationale.md ← por qué (corto, deliberadamente subespecificado)
contracts/ ← JSON Schemas que validan la instancia
integrations/ ← contratos con terceros: mapas, reservas, formularios, fotos
eval/ ← cómo se juzga la regeneración (must-have, judge prompts, lighthouse)
stack/ ← decisiones técnicas fijas
technical.md ← framework, lenguaje, deploy
conventions.md ← layout del repo, naming
components.md ← patrones canónicos de componentes
instance.example/ ← datos concretos del producto (variable)
README.md ← guía de personalización paso a paso
brand.md ← la marca, en prosa
config/ ← i18n, integraciones, site
content/ ← menú, restaurante, historia
overrides.md ← divergencias documentadas desde species
24 archivos en prosa o YAML. Los JSON Schemas no los cuento porque son infraestructura para la máquina, no ADN. Si un colaborador edita un schema, está cambiando cómo se valida la instancia, no cambiando lo que el producto es.
Las tres capas del post anterior (lo que el sistema hace, cómo lo hace bien, por qué lo hace así) viven los tres dentro de species/, como capabilities.md, quality.md y rationale.md. Son los archivos que más reescribí durante el experimento. El resto es la infraestructura que rodea esas tres capas y permite que un agente las ejecute sin supervisión humana.
Una decisión que me llevó tiempo: separar species/ de stack/. El species dice qué tipo de producto es (un restaurante con menú, reservas, mapa). El stack dice con qué herramientas se construye (Astro, TypeScript estricto, deploy estático). Los separo a propósito porque el species debería sobrevivir a un cambio de stack en dos años. Cuando aparezca un framework mejor en 2028, no migro código: regenero desde el mismo species con stack distinto.
instance.example/ es la pieza variable. Cuando alguien forkea el blueprint, copia instance.example/ a instance/ y edita ahí su producto concreto. El resto es reutilizable entre fork-ers.
Esto no es raro, cualquiera que haya documentado un proyecto ha escrito archivos parecidos. La diferencia es que aquí la estructura está pensada para que un agente la lea de principio a fin y construya el producto sin volver a preguntarte nada.
¿Te gusta lo que lees?
Unete a otros ingenieros que reciben reflexiones sobre carrera, liderazgo y tecnologia cada semana.
Donde tu ADN no llega, el agente improvisa
Lo cuento con dos ejemplos del run #1.
Ejemplo 1: la barra de navegación invisible. Era translúcida, flotando al hacer scroll. Sobre fondos oscuros se leía, pero sobre los párrafos de fondo claro se volvía invisible. Texto blanco sobre fondo blanco. Pasaba la accesibilidad estática (los ratios de contraste se medían contra el fondo declarado en CSS, no contra lo que de verdad había detrás). Suspendía la prueba humana a los dos segundos.
No era un bug del agente. Era un hueco en el ADN. Yo no había escrito en ninguna parte "la legibilidad de elementos persistentes se mide contra el peor backdrop posible que pueden solapar". Y como no estaba escrito, el agente decidió por mí. Razonable, además: hizo lo que hace el 80% de las landings que hay en internet. Esa regla, escrita una vez después del run #1, ahora vive en species/quality.md bajo el epígrafe "Persistent UI legibility". Cualquier blueprint que la herede ya no tropieza con esa piedra.
Ejemplo 2: el mapa que no era mapa. Tenía una capability que decía "mapa interactivo de la ubicación con tiles de OpenStreetMap". El agente entregó "una dirección de texto bonita con un enlace a Google Maps". Pasaba Lighthouse, pasaba accesibilidad, pasaba todo. Pero había decidido por mí que un Leaflet (una librería estándar para mostrar mapas con zoom y arrastre, no una imagen estática) era complicado, y bajó el contrato a su forma "razonable" más cercana, sin avisar.
Hasta que no convertí esa capability en MUST estricto en species/capabilities.md con criterio adicional ("mapa interactivo significa un Leaflet renderizado, no una dirección de texto con enlace a OSM"), el agente me iba a seguir simplificando lo que le pareciera que sobraba.
El patrón es este: el agente toma atajos invisibles cada vez que tu spec no es explícita. Y los atajos no son neutrales: cada uno mete un grado de fragilidad que no aparece el día que despliegas, sino tres meses después, cuando hay que tocar el sitio y nadie se acuerda de por qué algo está como está. El informe DORA 2025 ya está empezando a documentar esa correlación en datos.
Lo que no esperaba: estos atajos son el regalo más útil del experimento, no el bug. Cada uno es una piedra con la que las próximas regeneraciones ya no tropiezan. La regla del navbar, escrita una vez, sirve para todos los blueprints de la colección. El criterio del mapa lo mismo. Cada gap descubierto es leverage acumulable.
Lo bueno es que el protocolo del blueprint los recoge formalmente. El AGENTS.md exige al agente entregar, además del sitio, un archivo instance/.generated/dna-gaps.md donde lista todo lo que tuvo que decidir sin guía. Ese archivo es el output más valioso de cada regeneración. Si sale corto es señal de alarma: o no había gaps (improbable) o el agente tapó ambigüedad sin reportarla (lo normal). Cuando lo lees, sabes exactamente qué reglas escribir antes de la próxima.
Pero el ADN no debe ser exhaustivo
Yo entré al experimento creyendo que el ADN tenía que ser exhaustivo, formal, cerrado. Salí pensando lo contrario.
El brand.md de Mòs era prosa de tres páginas. Sin tokens hexadecimales, sin tipografías predefinidas. Una de las líneas decía: "Penumbra cálida. La luz no llega del techo, llega de las mesas: velas y un par de lámparas bajas con bombillas de filamento." Otra: "No queremos turistas que buscan paella en una terraza." El agente leyó eso y derivó una paleta cálida y oscura, una tipografía con peso, fotos con baja iluminación, copy sin clichés turísticos. Cuando regeneré con el run #2, la tipografía bailó entre dos opciones razonables, pero el carácter del producto se mantuvo idéntico.
Y por eso parte del ADN tiene que estar deliberadamente subespecificada, y el agente rellenando con juicio es una feature, no un bug.
Si cierras la marca demasiado (tokens hexadecimales, layouts predefinidos, reglas formales), el producto pierde personalidad y se siente como una plantilla. Y la sensación de plantilla es, hoy, el síntoma número uno del software hecho con agentes mal usados. Lo nota cualquiera. La gente cierra la pestaña.
Si la dejas demasiado abierta, el agente improvisa hacia el promedio del corpus, que es la estética de SaaS landing genérica: hero gradient, glass card, "trusted by" con logos en grayscale, tres iconos en fila con palabras de una sílaba debajo. El patrón por defecto del 2025.
El equilibrio es escribir prosa con voz, pero con un test final del tipo "si X persona en Y situación abre la página, ¿qué siente en diez segundos? Si no es esto, el diseño está mal". El agente usa esa frase como ancla. Y eso resuelve el problema mejor que cualquier sistema de tokens cerrados.
Para mí cambió dónde tenía que poner el cuidado: pasé más tiempo decidiendo qué dejar subespecificado en brand.md que el que me hubiera costado elegir cualquier token hexadecimal.
Por qué esto es complementario al harness engineering
En febrero, Mitchell Hashimoto le puso nombre a una disciplina relacionada: harness engineering. Diseñar el entorno donde el agente opera (tools, verification loops, AGENTS.md, sandboxes). En semanas pasó de blog post a término estándar: OpenAI lo recogió tras su experimento con Codex, Martin Fowler lo formalizó, Anthropic lo adoptó. Es buena disciplina y va a estar bien tenerla en el equipo.
Pero asume un proceso iterativo: un agente que trabaja durante días o semanas, un AGENTS.md que crece cada vez que el agente comete un error nuevo. Hashimoto añade una regla cada vez que algo falla. El equipo de OpenAI escribió un millón de líneas con Codex a lo largo de cinco meses con un harness que fue evolucionando.
Eso funciona muy bien para una clase de tareas: codebases que crecen, agentes que conviven con el equipo todos los días, contexto que se acumula. Deja fuera otra clase distinta: cuando le pides al agente que regenere un producto entero desde cero, en una sola pasada, sin haber estado allí antes. Ahí no hay oportunidad de iterar el harness. La calidad del producto depende íntegramente de la especificación con la que el agente arrancó.
Para una tarea iterativa, un buen AGENTS.md basta. Para construir un producto entero de cero hace falta más: estructurar la entrada en capas. Y eso es lo que estoy llamando ADN. La calidad del resultado se decide en la especificación inicial, no en la capacidad del agente.
El repo, como evidencia
Hoy abro github.com/EmilioCarrion/product-blueprints: cuatro blueprints en v0.1, con sus capabilities verificables, sus invariantes y su contrato de marca. La primera regeneración pública (Mòs) está hospedada para que se pueda navegar en vivo: galería de ejemplos.
Solo el de restaurante está validado por dos regeneraciones reales. Los otros tres son estructuralmente correctos pero no han sido ejecutados de extremo a extremo. Lo digo claro porque la diferencia entre "framework" y "framework probado" importa, y porque ya he visto suficiente Twitter de IA como para no querer caer en el lado equivocado de esa frontera.
¿Por qué publicarlo ya, si solo uno está validado? Por dos razones. Una, los necesito yo: cuando un compañero me pregunte cómo arrancar la web de su side project, le voy a pasar uno de estos. Dos, la única manera de descubrir los gaps que yo no he visto solo es que más gente regenere. Cada gap es leverage para el siguiente que pase.
Donde puedo estar equivocado
Dos sitios concretos donde mi modelo puede romperse, y los pongo encima de la mesa.
Uno, no sé si las tres capas del ADN escalan más allá de productos públicos pequeños. Un dashboard interactivo con estado, una app móvil con coordinación cliente-servidor, un e-commerce con inventario y pagos: ahí las capas pueden reorganizarse, o pueden hacer falta más. Lo que tengo funciona para cuatro géneros. Eso no es prueba general.
Dos, los atajos concretos que cuento (el navbar invisible, el Leaflet degradado) son contingentes a este modelo y este momento. Cuando GPT-5 se quede obsoleto en seis meses, los ejemplos van a parecer pintorescos. El patrón general (el agente rellena donde el ADN calla) creo que se mantiene. Pero "creo" no es "demuestro".
He estado equivocado antes sobre cómo iba a evolucionar la ingeniería de software. Es posible que esté equivocado ahora.
Pregunta para ti
Si tu trabajo incluye productos públicos pequeños (landings, microsites, sitios de eventos), forkea uno de los blueprints, escribe un instance/ para algo tuyo, y lánzale un agente.
Lo que más me sirve es el dna-gaps.md que el agente produzca, no el sitio en sí. Ese archivo es la lista de sitios donde el ADN guardó silencio y el agente tuvo que decidir. Súbelo como issue o PR, o mándamelo por correo.
Y si trabajas en un equipo donde se está adoptando IA en serio, la pregunta que merece la pena es: ¿estamos midiendo lo que el agente produce, o la calidad del ADN con el que producimos? Si es lo primero, vamos en la dirección que los datos DORA ya están castigando.
El ADN solo se hace mejor cuando se intenta escribirlo de verdad.
Este contenido fue enviado primero a mi newsletter
Cada semana envío reflexiones exclusivas, recursos y análisis profundos sobre ingeniería de software, liderazgo técnico y desarrollo de carrera. No te pierdas el próximo.
Únete a más de 5,000 ingenieros que ya reciben contenido exclusivo cada semana
Articulos relacionados
Cuando los LLMs generen miles de tokens por segundo, lo que importa no será el código
Si regenerar es más barato que mantener, la estrategia racional no es cuidar el código. Es hacer que sea desechable por diseño e invertir en lo que no es desechable. El futuro del ingeniero es escribir ADN, no código.
Operar la IA es fácil. Dirigirla es el oficio.
Cuando todo el mundo usa IA a diario, dominar la herramienta deja de ser un diferencial. Lo que importa es la posición que adoptas frente a ella: operar o dirigir. Y ningún agente da la cara por ti.
La disciplina no escala. La verificación necesita infraestructura.
La disciplina individual como sistema de calidad es un diseño frágil. Los tests escalaron porque se convirtieron en infraestructura. La verificación necesita hacer lo mismo.
